
Hello, I am Burak, an application architect and currently working as the Lead SRE for the Rakuten Car Auction Service. My role is to support our team by providing system architecture guidance and ensure high system reliability for our products.
In this post, I would like to introduce Hasura, a GraphQL server implementation written in Haskell, which allows software teams to build scalable, extendable and high-reliability graphQL API servers with much less effort than before.
Why GraphQL (and not REST)?
Picking REST or GraphQL for your API, has been a hot topic of ongoing discussions since the emergence of these technologies, but there can be no absolute answer to the question: “which one is the best?”. As with any engineering problem, choosing the right tool depends on the situation, considering requirements, environment, constraints and all the other factors.
For a very comprehensive comparison between Rest and GraphQL, you can refer to this nice blog post by the Rakuten Rapid API team.
Within this perspective, GraphQL is very efficient when a product needs a backend api that can serve different types of clients and the schema of data being queried needs to be extensively dynamic. GraphQL provides the flexibility to the teams to build very comprehensive and extendable backend APIs in an agile way and contributes highly to the total development costs.
Isn’t building a GraphQL API hard?
Yes, there is a big gap between building something and building something good, especially if we are talking about production ready, high-scale, reliable software.
Challenges of building a solid GraphQL Server are many, and require high skills and deep experience on several technical domains including but not limited to data, security and infrastructure. Although there are many libraries and frameworks on every major programming language to build GraphQL APIs, it is up to the developers to design and implement the specification accordingly. While this is empowering for the team and gives full control over all the details, it may also lead to missing best practices, skipping critical security measures or basically just leaving out performance gains.
Shortly, it is a heavy task and can cost a lot to achieve well.
Hasura to the rescue
In simple terms, Hasura automatically generates a GraphQL API for your data source and provides an HTTP server to access it. It starts the server with the bare minimum requirements, and then lets you configure and extend the functionality with parameters, environment variables, or by just using the web-based UI.
Hasura provides many core GraphQL features such as CRUD resolvers, subscriptions and role-based authentication out of the box without requiring additional development. It is possible to extend the existing data schema by defining hooks or even integrating other GraphQL APIs by adding remote schemas. Hasura handles the query optimizations automatically so developers do not need to concern about the details such as the infamous N+1 problem. Finally, it offers a managed software as a service plan, if teams need to delegate operations and want to ensure enterprise grade technical support.
Installation
There are several ways to install and run a Hasura GraphQL Server. The simplest way would be to create an instance at cloud.hasura.io and connect to it but for this post I would like to share the steps to run a Hasura server within a Kubernetes cluster. Please check the appendix section at the end of this post for the yaml files.
There is also an official docker installation guide, if anybody wants to try it quickly on a local docker environment.
For the Kubernetes deployment, we need to have a cluster ready, and this time I will use minikube for the demonstration purposes, but any standard Kubernetes cluster would suffice.
Installing Minikube is very straightforward (but out of scope of this guide) and we can just start it easily with the following command.
>>minikube start -p hasura-guide --memory=4096 --cpus=2 --kubernetes-version=v1.23.1<<
After the access to the k8s cluster, we first need to install a database for Hasura’s metadata. Hasura runs as a stateless application and requires a Postgres database to store its configuration and runtime data. This lets us scale the Hasura server and databases independently in the future.
We will start a basic PostgreSQL instance with applying the postgresql.yaml file. Please note, this file inlines the username and password “zeckon” as a k8s secret for simplicity, and this should be handled more securely in a production environment.
This configuration creates one PostgreSQL replica with a 512mb storage, which should be enough for our starter guide.
>>kubectl apply -f postgresql.yaml<<
After confirming the database has started and is running, we can simply start the Hasura instance by applying the hasura.yaml. Again, please reconsider securing the secrets and refactoring this yaml file too if would like to use in a real environment.
>>kubectl apply -f hasura.yaml<<
If everything went right, you should see the PostgreSQL and Hasura pods running successfully. At this point, we only need a port-forward to Hasura pod and visit http://localhost:3000/ to access Hasura Admin UI and test our setup.
>>kubectl port-forward pod/hasura-6b9cf87c6-2sw8v -n hasura 3000:80<<
And we can see the login screen, which we can use the password “zeckon” to enter.

Creating the Basic CRUD queries and mutations
After the login, we immediately arrive at the “API” tab, which allows us to consume and test our GraphQL API. This tab provides a graphiql section which experienced GraphQL users may already be familiar with. There also some extra parts to modify request headers and explore existing queries.
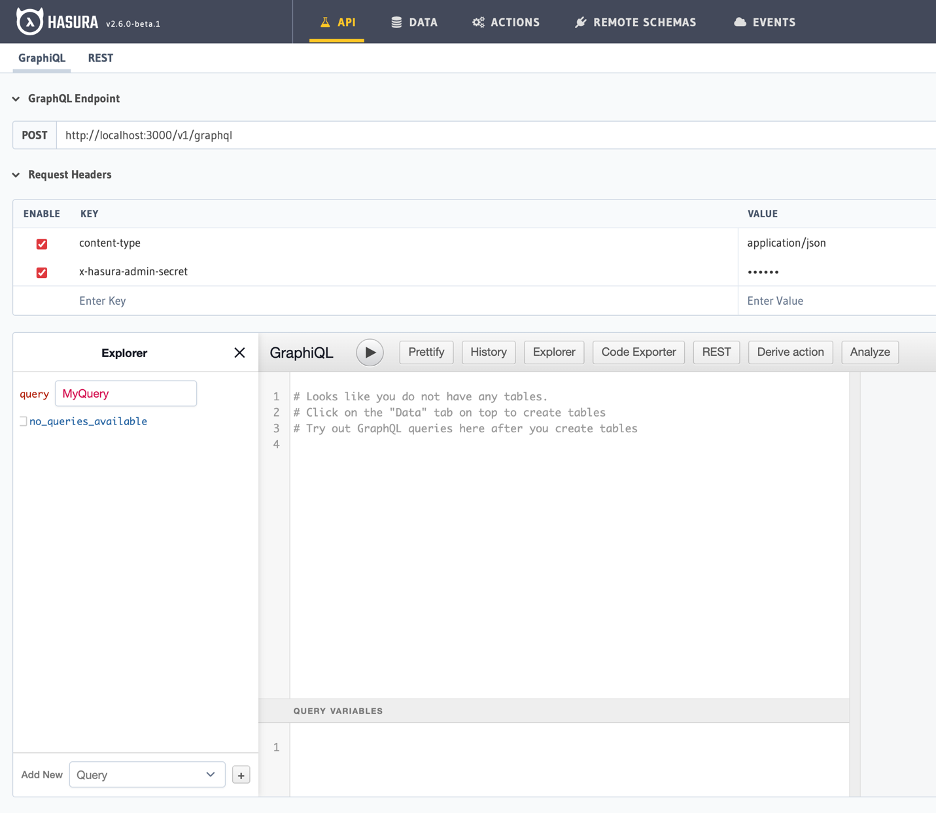
Next, we need to define our data sources. For this, we go to the “DATA” tab. Here from the “Data Manager” section, we can add databases to source our data. There was already a DB configuration in the hasura.yaml we applied, so a public schema shows up on the left.

We can directly create our tables from this screen, or by using any other database management tool. For the latter, we also need to tell Hasura which tables to track so it can generate the resolvers for our GraphQL API. For now, let’s add a basic “user” from the UI.

After creating the table from the UI, Hasura automatically tracks it and generates all the necessary CRUD queries and mutations. We can immediately check and try the newly generated API from the “API” tab.
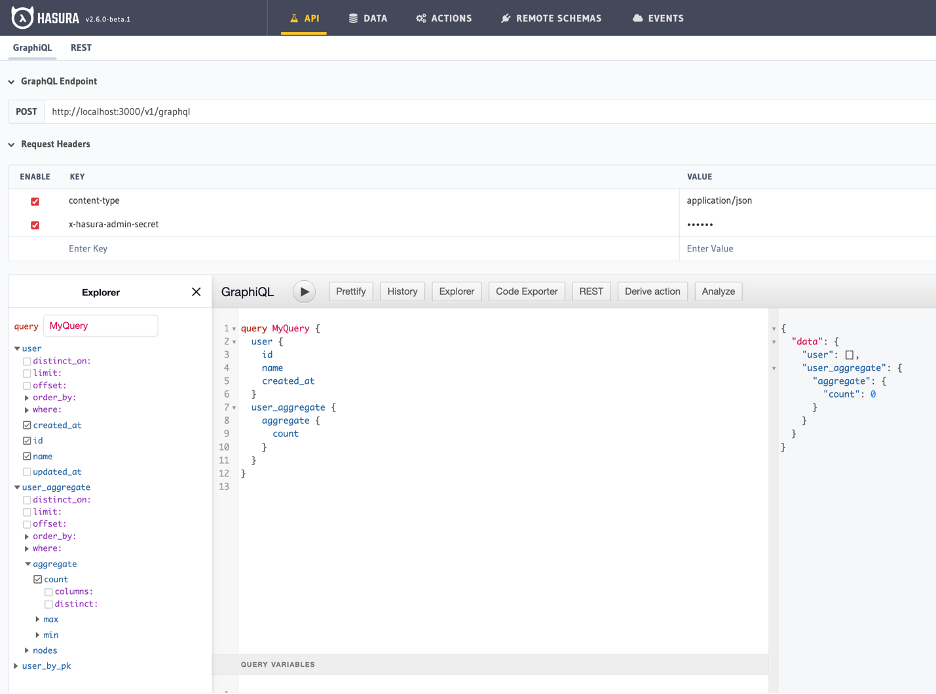
Access Control
In Hasura, access control is based on roles. There is a very comprehensive documentation so I will skip the details for now, but basically, each GraphQL request to the server will be authenticated either by a webhook or using JWTs, to identify the “role” of the request. Then, this “role” is employed by the Hasura server to decide the access level to the GraphQL schema.
By default, all queries, mutations and fields are accessible by the “admin” role. For this reason, admin access to the server should be carefully managed. Any request without authorization headers is considered “anonymous” role and cannot access to any part of the API by default.
From the “DATA” tab, other roles can be created, and can be configured from the “permissions” section on each table’s view. Here in this example, I am setting the “user” table’s select permission with a rule that, a request from a “user” role can only select rows that match “ID” column with requests “X-Hasura-User-Id”. This limits “user” roles to view only their own records. “X-Hasura-“ values are provided by the authentication service and allows implementing fine-grain access control at row and even column level.

From the “API” tab, we can test our “user” access rule. Please note, “API” tab allows to spoof “role” and “user-id” values to test different access roles and scenarios, in the real world, these values will be provided by the backend authorization layer and cannot be set by the user.
Here, we can see confirm “user” can only has access to “user” query and can only view own record.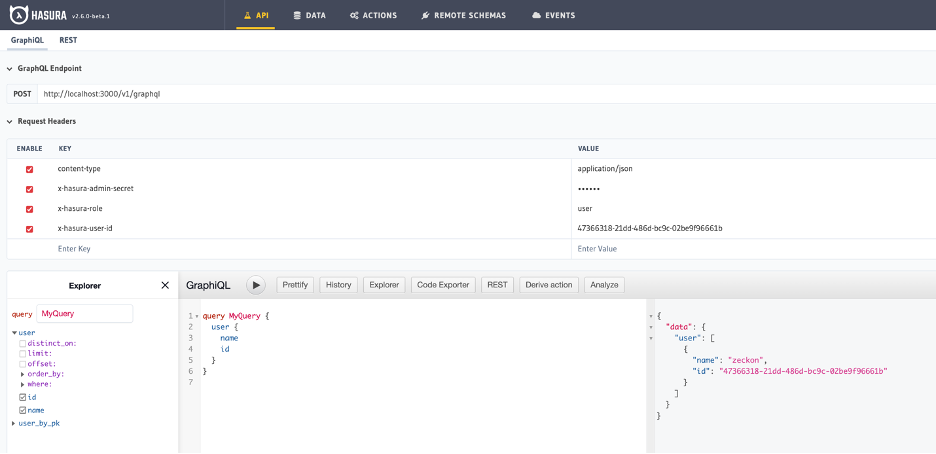
Extendability
Hasura provides several options to customize and extend the API generated. It allows teams to implement more complex business logic than basic CRUD operations and lets them integrate their existing services without much effort.
First and the most straightforward way to implement some custom behavior is using native PostgreSQL features. Hasura allows us to create database functions and use them to calculate “computed fields” or modify values during insert or update operations. Database views can also be created to expose the results of a custom query as a virtual table. This type of extendibility is especially useful for data validation and basic transformations. “SQL” section can be found on the “DATA” tab to run any SQL statement directly on the database.

The second and more powerful way to extend Hasura functionality is “Actions”. Actions can be used for almost every type of customization from data manipulation to utilizing third party services. Basically, developers can create additional GraphQL queries or mutations that will invoke an external HTTP endpoint, which will implement the required logic and return the result back to Hasura to be passed as part of the GraphQL response. External endpoint receives all the necessary metadata including authentication, parameters and context, so it can virtually implement any kind of logic, to satisfy the business requirement. Actions can be synchronous or asynchronous, which latter returns an action ID to achieve for more complex flows.
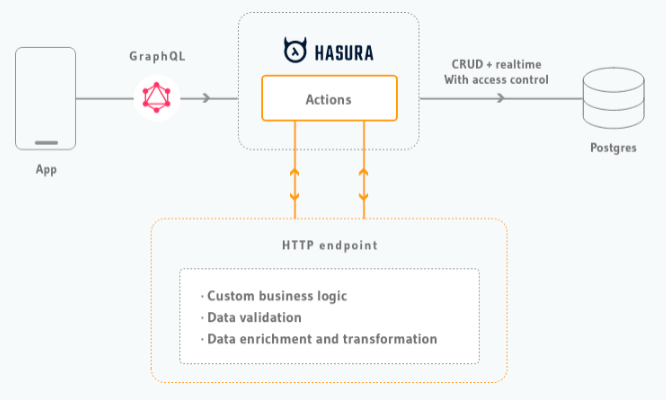
The third option is “Event Triggers”. They are executed when data on the specified tables are altered and invoke external endpoints to carry out a custom logic. They are almost similar to “Actions” but the invocation condition is based on database state rather than the user query or mutation. Triggers can also be run manually if needed or can be scheduled via cron configuration. Triggers are especially useful to do data transformation or create any kind of automation and scheduled tasks.
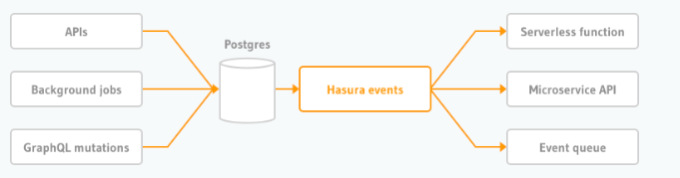
The final and the most powerful option (in my opinion) is “Remote Schemas”. In Hasura, teams can define other GraphQL APIs as “Remote schemas” to create and provide a unified GraphQL API. These external APIs may have been implemented in any platform or framework, but Hasura will stitch the schemas into a single GraphQL API.
Remote schemas also let us define relations between these separate external APIs to make complex joined queries possible as well as use common authorization rules to control access levels.
This advanced functionality makes integrating or migrating existing APIs so easy and provides many possibilities to create comprehensive unified backend APIs.

Conclusion
This was a brief introduction and short guide for the usage and features of Hasura GraphQL Server. We are hoping to share more details and complex use-cases in the future.
It is a very active project and getting many updates frequently so please keep an eye on the project and product pages.
Finally, If you are interested working in a very dynamic environment and use the latest technologies, why not have a look at the available positions at Rakuten?
Appendix
Here are the yaml files used to deploy in the guide:
postgresql.yaml
apiVersion: v1 kind: Namespace metadata: name: postgresql labels: istio-injection: enabled --- apiVersion: v1 kind: Secret metadata: name: postgresql-secret namespace: postgresql type: Opaque data: POSTGRES_USER: emVja29u POSTGRES_PASSWORD: emVja29u --- apiVersion: v1 kind: ConfigMap metadata: name: postgresql-config namespace: postgresql data: POSTGRES_DB: "zeckon" --- kind: PersistentVolumeClaim apiVersion: v1 metadata: namespace: postgresql name: postgresql labels: app: postgresql spec: capacity: accessModes: - ReadWriteOnce resources: requests: storage: 512Mi --- apiVersion: apps/v1 kind: StatefulSet metadata: name: postgresql namespace: postgresql labels: app: postgresql spec: serviceName: postgresql replicas: 1 selector: matchLabels: app: postgresql template: metadata: labels: app: postgresql spec: containers: - name: postgresql image: postgres:12 envFrom: - configMapRef: name: postgresql-config - secretRef: name: postgresql-secret ports: - containerPort: 5432 name: postgresql volumeMounts: - name: postgresql mountPath: /var/lib/postgresql/data volumes: - name: postgresql persistentVolumeClaim: claimName: postgresql --- apiVersion: v1 kind: Service metadata: namespace: postgresql name: postgresql labels: app: postgresql spec: ports: - port: 5432 name: tcp selector: app: postgresql hasura.yaml apiVersion: v1 kind: Namespace metadata: name: hasura labels: istio-injection: enabled --- apiVersion: v1 kind: Secret metadata: name: hasura-secret namespace: hasura type: Opaque data: HASURA_GRAPHQL_ADMIN_SECRET: emVja29u --- apiVersion: v1 kind: ConfigMap metadata: name: hasura-config namespace: hasura data: HASURA_GRAPHQL_METADATA_DATABASE_URL: "postgres://zeckon:zeckon@postgresql.postgresql:5432/zeckon" HASURA_GRAPHQL_DATABASE_URL: "postgres://zeckon:zeckon@postgresql.postgresql:5432/zeckon" HASURA_GRAPHQL_ENABLE_CONSOLE: "true" HASURA_GRAPHQL_DEV_MODE: "true" HASURA_GRAPHQL_ENABLED_LOG_TYPES: "startup, http-log, webhook-log, websocket-log, query-log" HASURA_GRAPHQL_ENABLE_TELEMETRY: "false" HASURA_GRAPHQL_SERVER_PORT: "80" --- apiVersion: apps/v1 kind: Deployment metadata: namespace: hasura labels: app: hasura hasuraService: custom name: hasura spec: replicas: 1 selector: matchLabels: app: hasura template: metadata: namespace: hasura labels: app: hasura spec: containers: - image: hasura/graphql-engine:v2.6.0-beta.1 imagePullPolicy: IfNotPresent name: hasura envFrom: - configMapRef: name: hasura-config - secretRef: name: hasura-secret ports: - containerPort: 80 protocol: TCP - containerPort: 3000 protocol: TCP resources: {} startupProbe: httpGet: path: /healthz port: 80 readinessProbe: httpGet: path: /healthz port: 80 livenessProbe: httpGet: path: /healthz port: 80 --- apiVersion: v1 kind: Service metadata: namespace: hasura labels: app: hasura name: hasura spec: ports: - port: 80 name: http-80 - port: 3000 name: http-3000 selector: app: hasura