

初めまして、「楽天ペイ(オンライン決済)」で Tech Lead として働いているNanaです。今回から2記事に分けて、私たちが取り組んでいる高可用性/耐障害性 (以下、HA/DR) の仕組み作りについて紹介していきます。
今回の記事では、私たちがこれまで「楽天ペイ(オンライン決済)」という大規模サービスを運営・管理する中で培ってきたHA/DRを高めるためのアプローチ方法を説明していきます。
また次回の記事では、私たちが運営する「楽天ペイ(オンライン決済)」でのより具体的な取り組みについても紹介する予定です。サービスのHA/DRを高めたいと考えている方は、是非ご覧ください。
楽天ペイ(オンライン決済)とは
私たち「楽天ペイ(オンライン決済)」では決済サービスを楽天市場以外のECサイトに提供をしています。エンドユーザ視点では、クレジットカード情報の入力といった面倒な作業をする事無く会員情報に事前に登録されているクレジットカード情報を利用したり、楽天ポイント・楽天キャッシュの残高を利用したりして簡単に決済することができます。
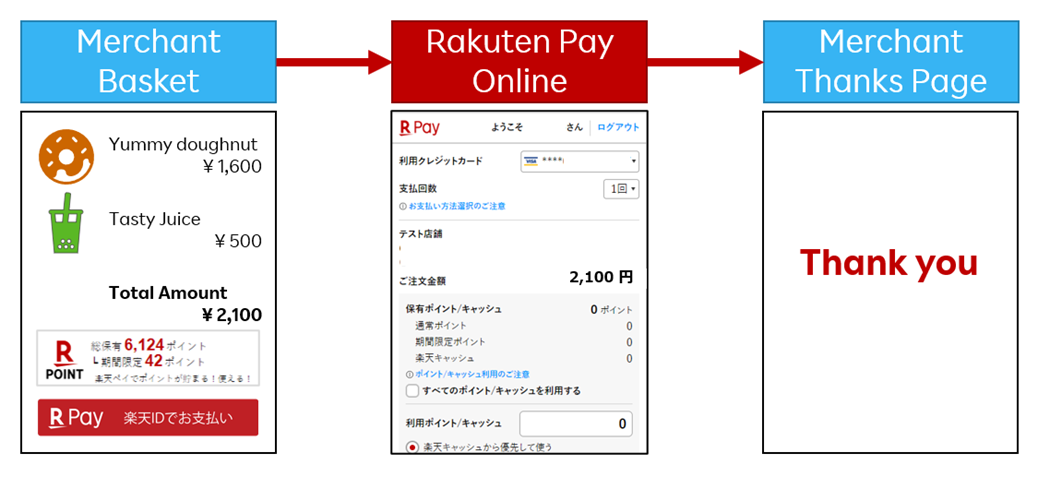
コロナ禍によってECサイトを利用する人が増えた後も継続してECサイトでの買い物をして頂けるようになったこともあり、おかげさまで楽天ペイ(オンライン決済)を選んで利用して頂ける方も増加を続けております。どのようなサイトで使えるのかは、以下のリンクをご参照ください。
使えるサイトについてはこちら
なぜHA/DRの向上が私たちにとって重要なのか
さて、ここからが本編です。上記の通り「楽天ペイ(オンライン決済)」は楽天市場以外の EC サイトへも提供されています。もし私たちのサービスが停止すると、ECサイト側でも決済不可となり購入者様にご迷惑をおかけすることはもちろん、ECサイト側の売上を落とすことにも繋がってしまいます。
そのため、私たちは根幹となる「楽天ペイ(オンライン決済)」のHA/DRを高めることを重視して日々開発・運用を行っています。
HA/DRを向上させるための5ステップ
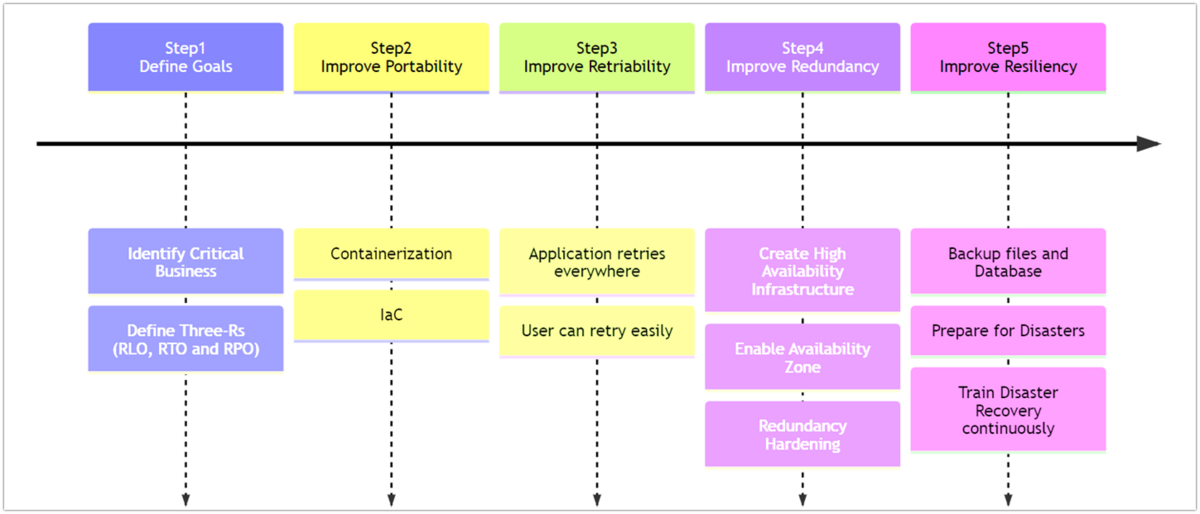
HA/DRを達成して行くためには上記のように大きく5つのステップがあります。それぞれのステップでの取るべきアクションはサービス規模や運用にかけるコスト、チーム体制などによって変わるので、一つ一つのStepを順番通りに確認してください。
Step1: HA/DRにおける目標を設定する
まず運用コストやチーム体制は事業継続計画 (以下、BCP) と密接に関わっているので、BCPで定義されている以下の3つの観点と費用について関係者と必ず認識を合わせましょう。
目標設定は現在のサービスのビジネス状況によって変化していきます。定期的に見直し、現在の立ち位置を考慮した目標を設定しましょう。
| 目標 | 目標の内容 | 決定のための要素 |
|---|---|---|
| RLO (Recovery Level Objective) / 目標復旧レベル | 最低限動かしたい機能は何か? 最低限どの程度の稼働率を目指すか? |
エンドユーザに使ってもらう主要機能は何か? 一時的に手運用で動かせる物や復旧を待てる業務はあるか? |
| RTO (Recovery Time Objective) / 目標復旧時間 | どの程度の時間で復旧を目指すか? | 楽観的なシナリオではどのくらいの時間がかかるか? 悲観的なシナリオではどのくらいの時間がかかるか? 停止している間の機会損失・社会的インパクトはどの程度か? 財務的にかけられる運用コストは?(掛け捨て保険) |
| RPO (Recovery Point Objective) / 目標復旧時点 | データの損失は、いつのタイミングまで許容できるか? | データの更新頻度はどの程度か? 損失するデータは別の手段で復旧が可能なデータか? データの保持に対して関連するような法令・規則等はないか? |
これら上記の3つのR、RLO/RTO/RPOはシステムの複雑度と運用コストに大きな影響を及ぼします。また万が一の障害発生時には、一部機能やデータを諦めるという決断を下さなくてはいけない場合もあります。そういった有事の際を含めた想定を行いながら、目標設定を行ってみてください。
特に後述するStep5 Resiliency (回復性)を向上させる為のアーキテクチャ設計には大きく影響するため、後回しにせず事前に目標設定を完了していることが望ましいです。
Step2: Portability (移植性)を向上させる
Step2ではPortability (移植性)を向上させていきます。移植性とは、開発したアプリなどの資産がどのような環境でも容易に動作し、また動作環境の再現も容易であるかどうかの程度を指します。移植性を向上させる主な目的は、「デリバリーの高速化」です。具体的にはコンテナ化やInfrastructure as Code (以下、IaC)の取り組みが当てはまります。
HA/DRを進めて行く上では、移植性の向上はチームとして取り組むべき最初の課題であり、開発スタイルや費用対効果といった課題にぶつかる最初の壁にもなります。
コンテナ化は比較的取り組みやすいと思いますが、IaCを取り組む場合には特に管理・教育コストの面で施策の難易度が高まります。最初に取り組むことをお勧めする理由としては、以下のような理由が挙げられます。
1.後続Step3~5の取り組みは、移植性を前提として進めて行くため。
2.後続Step3~5の取り組みが不十分であったとしても、費用と時間をかければ有事の際に復旧を目指すことができるため。
Step3: Retry-Ability (リトライ容易性) を向上させる
Step3では、Retry-Ability (リトライ容易性)を向上させていきます。この用語は私たちの造語ですが、以下の2つの観点がポイントです。
1. システム面では常にリトライ処理を実装し、リクエストが正常に処理されることを担保する
可用率をどれだけ改善しても100%とはなりません。ネットワークの瞬断や通信の滞留、フェイルオーバに伴う瞬断の発生を完全に防ぐことは難しいためです。そのためI/Oが発生する箇所(通信・ファイル書込等)では必ずリトライ処理を実装すると良いでしょう。
ただリトライ処理は単純なようでいて、実はデータの不整合を引き起こす原因になり得ます。たとえばConnection Timeoutとは違い、Query (or Read) Timeoutの場合はリクエストが送信され、処理が完了している可能性があります。
場合によっては後続処理を正とする単純なリトライ処理の実装のみで、十分に整合性を担保できることもありますが、より厳密なデータの整合性が求められる場合、モノリシックサービスであれば「トランザクション管理を行う」、マイクロサービスであれば「補償トランザクション」や「TCC (Try-Confirm/Cancel)パターン」等を作り込んでいく必要があります。今回は参考として、補償トランザクションを利用したリトライ処理の場合でのシーケンス図を以下に図示します。
[補償トランザクションの実装例]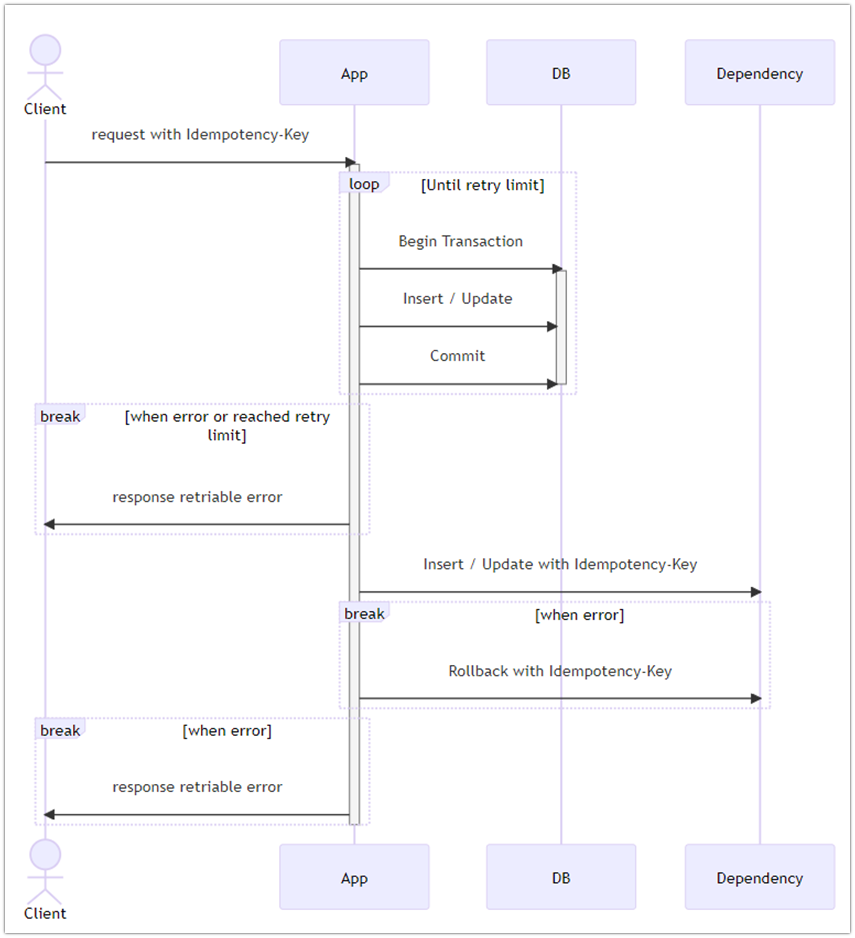
2. ユーザが簡単にリトライ処理を行えるようなシステム設計を行う
システム側でリトライ処理を実装していても、リトライをしきれないケースも発生します。そういった場合でも、後続処理がデータの不整合による影響を極力受けないようフェールセーフに配慮することが重要です。
対策の一例としては、後続処理を素早く再実行させるために利用者自身でも容易にリトライ処理を再実行できるようなシステム設計を行うなどがあります。そのためには、エラー発生時の処理フローや画面上の振る舞いと言った観点でもシステム設計を作り込んでおくと良いでしょう。
Step4: Redundancy (冗長性) を向上させる
Step4して、Redundancy(冗長性)を向上させていきます。冗長性の向上とは、システムを多重化することで、一部のシステムが不具合などで正常に動作しない場合でも、全体を通してシステムが正常に稼働する状態を目指すことです。
ただ冗長性を向上させる施策を行うことで、切り替えや切り離し処理が追加され、新たな瞬断の発生原因となる可能性があることにも注意が必要です。冗長性を向上させるための観点は以下の2点です。
1. High Availabilityを意識したインフラ構成を構築する
まずは、地道に単一障害点となる箇所をみつけ多重化・クラスタ化を進めていきましょう。
単一障害点とは、システムを構成する要素のうち、そこが停止するとシステム全体が停止してしまう部分のことです。
このとき多重化をする上での重要なポイントは、「NW・電源系統・仮想化サーバ等」が物理的に分離されていることです。これらの要素が分離されていることで、システムの可用性を担保することができるようになります。またクラスタ化を行う場合、アプリケーションのインスタンスが物理的に異なるサーバ上でも動作可能である必要があります。
サービスによっては、オンプレミスではなくパブリッククラウドなどを利用しているケースもあるかも知れません。その場合は、Availability Zoneを適切に設定することで可用性の高いインフラ構成を実現できます。
以下では、単一障害点となる可能性があるポイントをいくつかピックアップしてみました。まずは読者の皆さんも同様の観点でチェックしてみてください。
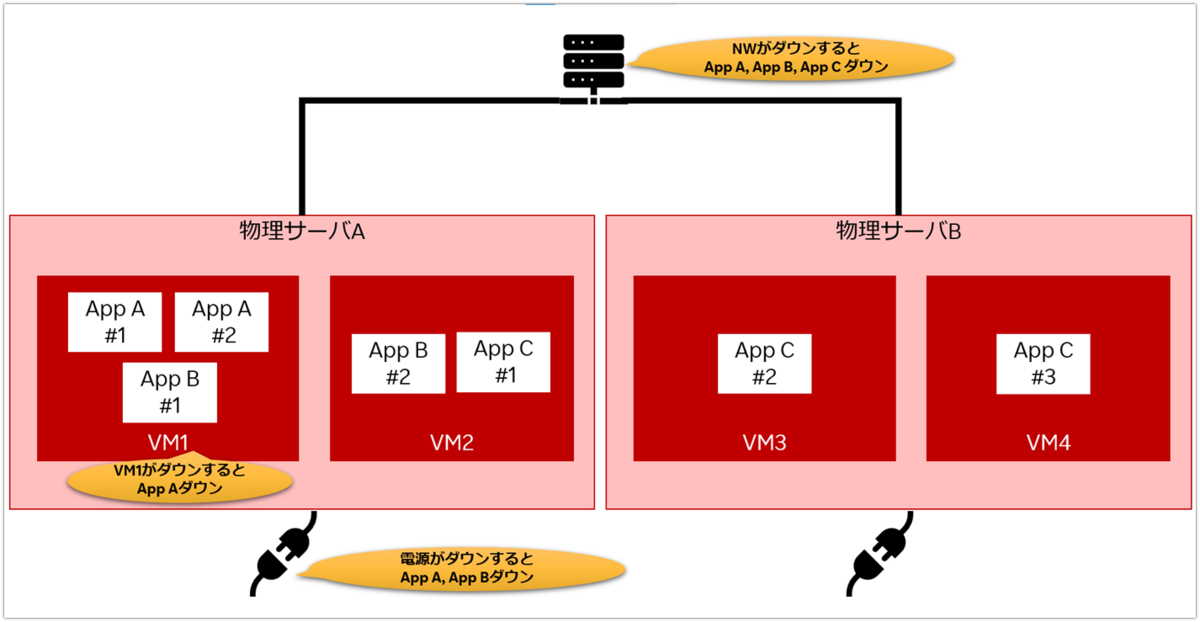
2. 冗長性を維持する運用手順を確立しよう
仮に冗長性の高い構成を組んでいても、ダウンしたサーバやアプリケーションへリクエストが送られる状態が長く続くとリクエストの成功率は低下します。そのため、素早く切り離しやフェイルオーバを行えるかといった運用手順の確立も重要なポイントです。
サービス開始時などは手動対応でも良いですが、運用を行いながら効率的な切り離しやフェイルオーバを行う手順を確立させ、最終的には運用手順を自動化させていけることが理想です。
Step5: Resiliency(回復性) を向上させる
Step5ではResiliency(回復性)を向上させていきます。回復性ではシステムが完全にダウンしてしまったときからでも復旧できるような状態を目指していきます。
これまでのStepでシステムを継続的に正常稼働させるためのポイントを幾つか紹介してきましたが、それでも常に、大規模な災害や停電などシステム全体が停止することが避けられないケースは存在します。そのような場合でも素早くサービスを復旧できるよう準備しておきましょう。
回復性を向上させる具体的な施策としては、「バックアップを確保する」「距離的に離れた地点でシステムを動かす」などが考えられます。実装する施策の選定には、施策実施時の運用費用、サービス復旧時間とサービス停止時の損失額などを試算し、施策毎の妥当性を検討する必要があるでしょう。例として、各施策実施時の運用費用とサービス復旧時間についての関係性を調査した際のグラフを以下に示します。
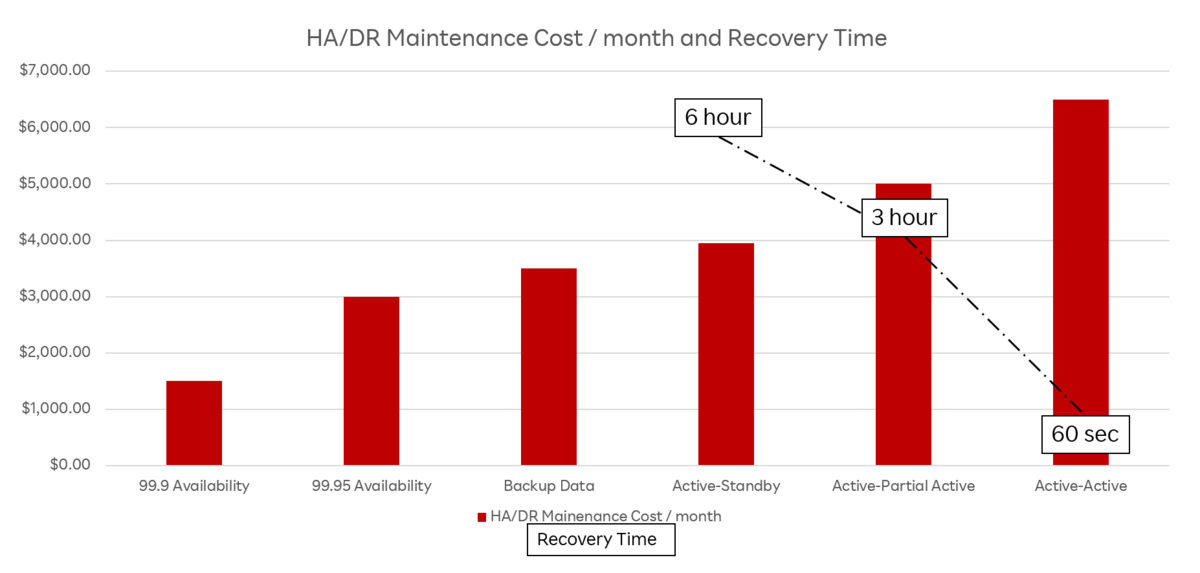
※データや数値はあくまで参考値です
上記のグラフからも、システムの規模やサービス停止時の損失額により、サービス毎に取るべき施策やKPIが異なってくることがわかります。復旧時間が短い強度の高い施策の場合、その分運用コストも肥大化していくため、サービスの成長・拡大のフェイズとともに徐々にActive-Activeを目指していくことが現実的な施策選定と言えそうです。
また非常時でもシステムの回復手順(フェイルオーバの手順等)を作業者が素早く実行できるよう、定期的に手順書のアップデートやITシステムの防災訓練を行うなど、日頃から非常時の準備を行うことが重要です。
まとめ
ここまで読んで下さってありがとうございました。この記事を通して、読者の皆さんがHA/DRやBCPをより深く理解し、少しでも実際のアクションに繋げて頂けたら幸いです。
次回は、ここまで紹介してきたアプローチ方法を「楽天ペイ(オンライン決済)」の開発現場で実際にどう活かしているかについて具体例を交えて紹介していきます!
採用情報
私たちは一緒に開発をしてくれるメンバーを募集しています。詳しくは以下のリンクを参照ください。