

楽天ペイ(オンライン決済)で Tech Lead をしている Nana です。今回は私たちが運営する「楽天ペイ」での高可用性/耐障害性 (以下、HA/DR)を向上させるための具体的な取り組みを紹介していこうと思います。
前回の記事では、私たちが第一弾として「楽天ペイ」という大規模サービスを運営・管理する中で培ってきたアプローチ方法をより一般的な説明として取り上げました。興味のある方は是非合わせてご覧になってください。
HA/DRを向上させるための5ステップ
前回の記事でもHA/DRを達成していくための5つのステップについてはお伝えしていますが、再掲です。「楽天ペイ(オンライン決済)」を運営している私たちのチームでも以下の5つのステップ通りに沿って、HA/DRを向上させています。
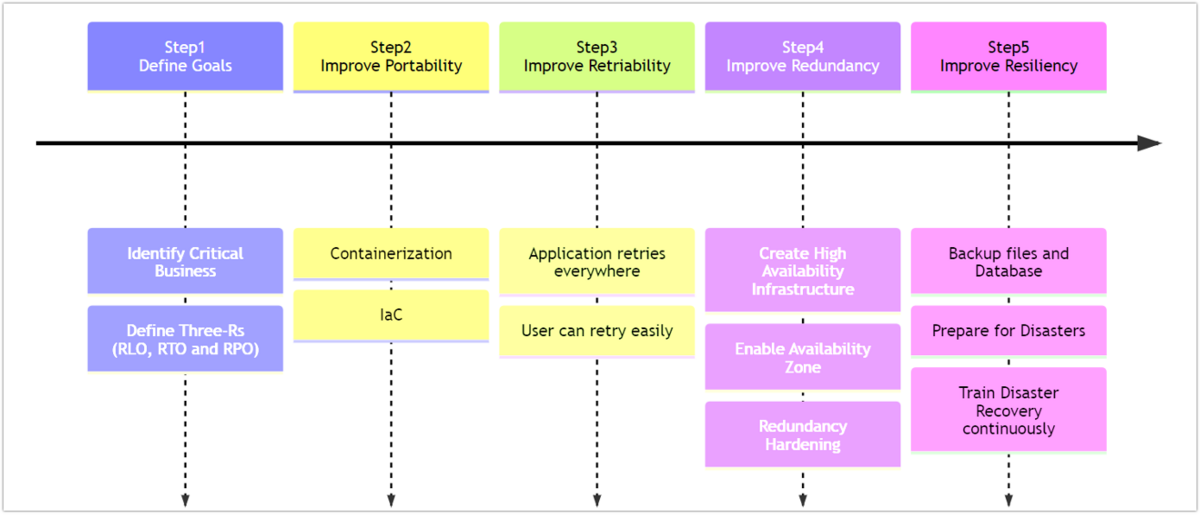
5ステップとは?
Step 1. HA/DRにおける目標を設定:事業継続計画 (BCP) における3つの(RLO/RTO/RPO)を設定する
Step 2. Portability (移植性):開発したアプリなどの資産がどのような環境でも容易に動作し、また動作環境の再現も容易である状態を目指す
Step 3. Retry-Ability (リトライ容易性):処理フローにリトライ処理を含める、あるいはユーザー操作によるリトライ処理を可能にするなど、リトライ処理が容易に行えるシステム設計を目指す
Step 4. Redundancy (冗長性):システムを多重化することで、一部のシステムが不具合などで正常に動作しない場合でも、全体を通してシステムが正常に稼働する状態を目指す
Step 5. Resiliency(回復性):システムが完全にダウンしてしまった場合でも復旧できるような状態を目指す
詳細は、前回の記事をご覧ください。
Step 1: HA/DRにおける目標を設定する
※社内戦略や具体的な数値などが含まれてしまうため割愛します。
Step2: Portability (移植性)を向上させる
私たちの場合、機能やサービス毎にアプリケーションレベルではコンテナ化、インフラストラクチャレベルでコード化できる部分をそれぞれ整理し、移植性を担保する取り組みを行なっています。
1. アプリケーションレベルでのコンテナ化
主にアプリケーションレベルでのモジュール化とは、コンテナ化を意味します。コンテナビルダーとしては、最新のトレンドとしてはBuildpacksの利用もあり得ますが、私たちは現在Dockerfileを用いてイメージ化しています。
Dockerfileを利用する場合は自由度が高い分、セキュリティ、再現性の観点で事故が発生しやすくなります。防止策として全アプリケーションが共通して利用するベースイメージを準備しておき、それらを各アプリケーションで利用することで事故を防ぐ工夫を行っています。
2. インフラストラクチャレベルでのコード化
インフラストラクチャにおけるコード化は、Infrastructure as Code(以下、IaC )とも呼びます。IaCの取り組みを進めた上で、サービスの拡大と共に徐々にインフラ構成をモジュールとして利用できるよう準備すると良いでしょう。
私たちの場合、Terraformを利用してActive・Standby用の複数環境のインフラ構成を一括で管理しています。統一化されたモジュールを利用することで最小の設定で効率的に複数の環境を構築・管理することができます。
IaCを進めていく上で重要なことは、手作業を廃し、メンバー全員にインフラストラクチャに対する理解を深めていくよう促すことです。手作業は再現性を低めバグや想定外のエラーを発生させる原因となります。手作業を排除していくためには、全てのエンジニアのインフラストラクチャに対する苦手意識(特にNW、セキュリティ周り)を取り除き、メンバー全員がIaCへの理解を深めた状態となるのが理想です。
私たちのチームでも、約2年の歳月をかけて徐々にチームメンバーへIaCを基準とした開発体制を浸透させていく事ができました。例えば、インフラの構成変更が発生するような場合、アプリケーションエンジニアに対してインフラエンジニアがレビュアーとして協力できる体制を作る、あるいは機能開発前にアプリケーション・インフラエンジニアを交えて設計する等、小さな成果を積み重ねてきました。それでも常に改善の余地があるため、現在でもメンバー同士でさらに良いインフラ構成について考えています。
Step3: Retry-ability (リトライ容易性) を向上させる
「楽天ペイ(オンライン決済)」の場合では、エラーが発生した際でも単にデータの不整合がなく処理前の状態へリカバリさせるだけでなく、データ処理を完了させた状態へ前進させることを目標としています。
一般的にはいくつかのリトライに関わるデザインパターンがあり、例えば補償トランザクションなどではエラーが発生した際には処理のキャンセルをかけていきますが、私たちのサービスでは、なるべく決済処理を完了させられるよう一度依存サービス側のステータスを確認し、処理に進めるか戻すかを決定するようなロジックを取っています。そのため場合によっては、再度リクエストを投げることなく意図した処理が完了させられます。
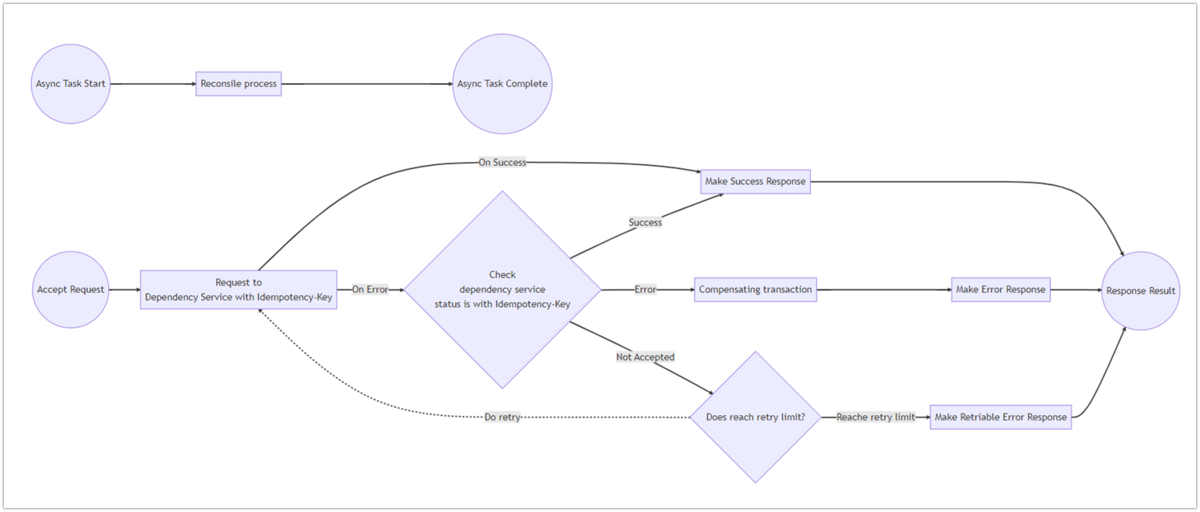
また依存サービスとの通信が断続的に失敗しているケースでは、キャンセル処理の通信が失敗してしまうので補償トランザクションのみではデータの整合性を完全に担保することはできません。そういったケースを想定し、別プロセスで定期的に依存サービスとの不整合を解消するための突合処理(Reconcile Process)を非同期処理として行い、補完的にデータの整合性を担保しています。
Step4: Redundancy (冗長性) を担保する
私たちの場合、パブリッククラウドを利用しているため、インフラレイヤーでは基本的にはAvailability Zone(以下、AZ)を有効にした上で、インスタンス数を2以上にすることで冗長性を担保しています。アプリケーションレイヤーではAZにまたがるKubernetes (以下、k8s)上で動かしながら、インスタンス数を2以上にすることで冗長性を担保しています。しかし、実はこれだけではアプリケーションレイヤーの可用性は完全ではありません。
k8sでは更に可用性を上げるため、以下のような設定を行っています。
| 設定項目 | 設定で防ぎたいこと・やりたい事 |
|---|---|
| PodDisruptionBudget | ノード故障で再起動時したいときに、Podが同時にダウンすることを防ぐ |
| ResourceLimit | 特定のアプリケーションによる負荷が上昇した場合、他のアプリケーションの性能に影響を及ぼさないように占有できるリソースを制限する |
| LivenessProbe | 正しく動作していないPod(Broken Pod)がそのまま実行状態となりリソースを占有したままの状態となることを防ぎ、再度処理を実行させる |
| ReadinessProbe | 処理が失敗する可能性が高いPodを安全に切り離す |
| NodeSelector & NodeAffinity | 特定の負荷が高いバッチとエンドユーザーに影響するフロントアプリケーションを物理的に分割し、エンドユーザーの利用に影響が出ないようにする |
| PodAntiAffinity | あるアプリケーションを稼働させるためのPodを複数Nodeをまたいでデプロイされるようにし、1つのNodeで障害が発生した場合でも、サービス全体が停止しないようリスクを分散させる |
上記の設定については、以下のようなDeployment Yamlファイルにて設定が可能です。
Deployment Yaml
apiVersion: policy/v1
kind: PodDisruptionBudget
...
spec:
minAvailable: 50%
selector:
matchLabels:
app: <app-name>
...
apiVersion: apps/v1
kind: Deployment
...
spec:
replicas: 2
template:
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- <app-name>
topologyKey: "kubernetes.io/hostname"
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: app-category
operator: In
values:
- web
containers:
- name: <app-name>
…
resources:
limits:
memory: 1024Mi
cpu: 1000m
readinessProbe:
...
livenessProbe:
...
Step5: Resiliency(回復性) を向上させる
私たちは現在、複数のシステムを複数用意し待機させておくActive-Standbyの構成としていますが、一般的には以下のような3つの区分に分けて環境を準備します。事前にStep1で設定した目標復旧時点(以下、RPO)や、どの程度の運用コストや復旧時間 (以下、RTO)を要するのかなどを計算し、最適な施策の組み合わせを検討した上で、実装しました。
HA/DRを進める上ではRTO/RPOと運用コストの間の費用対効果を高めるために、3つの区分をどのように組み合わせて環境構築するかがとても重要です。
| 区分 | 定義 | 運用コスト | 復旧にかかる時間 | |||
|---|---|---|---|---|---|---|
| On-Demand (Cold Standby) |
事前にバックアップ環境のコード化をしておくことで、必要に応じてTerraformでProvisioningをする。 *一般的Cold Standbyですが、クラウドでは停止=削除となる場合がある為、On-Demandと定義しています。 |
無 | 大 | |||
| Warm Standby | 事前にバックアップ構築をしておき、停止もしくは縮退運用にする。 | 小 | 中 | |||
| Hot Standby | 事前にバックアップ構築を構築し、常に起動させておくリソース。 | 大 | 無~小 | |||
また忘れがちですがOn-Demandで事前にバックアップ環境をコード化する際には、セキュリティ監査やNW系の設計・疎通を受けた上でリソースを削除して、再現性が高く安全にゼロから作ることを保証しましょう。
最後に本番環境と待機系の参考システム構成を図示します。特筆することとしては、ユーザからのリクエストはGSLBで常に受け付けており、また環境を速やかにスイッチできるよう本番・待機系の両環境へ事前に待機系のIPやドメインの情報を含むよう設計し、GSLB に登録させておきます。
k8sのwarm standbyについては想像がつきにくいかと思いますが、マスターノードのみを維持してアプリケーションはデプロイせずワーカーノードを0台として縮退運用をしています。もし問題が本番環境で発生した場合には、エンジニアは待機環境のリソース群の作成や、本番環境への昇格等を行った後にGSLBからの経路を変更することでシステム回復を目指します。
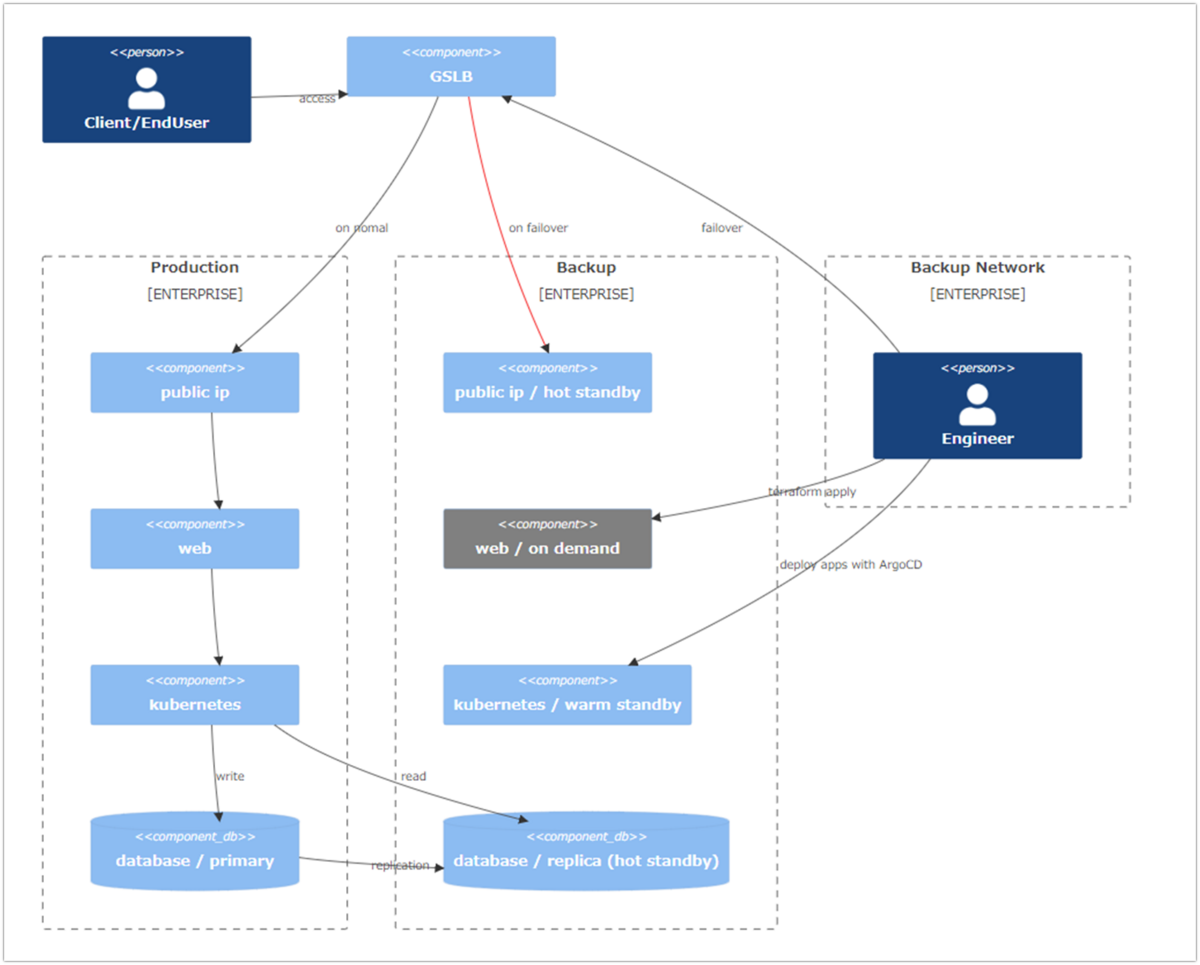
またいつ問題が発生した場合であっても速やかにバックアップ環境から本番環境への移行作業が行えるように、定期的にシステムの防災訓練をかねた手順の検証を行っています。
まとめ
いかがだったでしょうか。今回は、楽天ペイ(オンライン決済)で実際のインフラ構成に落とし込んだ場合での例をご紹介しました。
前回の記事と併せて、これらの記事が少しでも皆さんが実際にアクションを起こすための参考となれば幸いです。ここまで読んでくださってありがとうございました!
採用情報
私たちは一緒に開発をしてくれるメンバーを募集しています。詳しくは以下のリンクを参照ください。