

Hi, I’m Nana, the Tech Lead for Rakuten Pay (online payment). In this and the following article, I will introduce how we go about creating our High Availability/Disaster Recovery (HA/DR) framework.
This article will explain the approach to enhance HA/DR, which we have developed while operating and managing Rakuten Pay, a large-scale online payment service.
The next article will introduce more specific initiatives in the operation of Rakuten Pay (online payment). If you are looking to enhancing the HA/DR of your service, please check it out!
What is Rakuten Pay (online payment)?
We, Rakuten Pay (online payment), provide payment services to e-commerce sites other than Rakuten Ichiba. Rakuten Pay (online payment) allows users to effortlessly make a payment by using credit card information registered in advance in the membership information or by using the balance in Rakuten Points and Rakuten Cash, without having to go through the tedious process of entering credit card information.
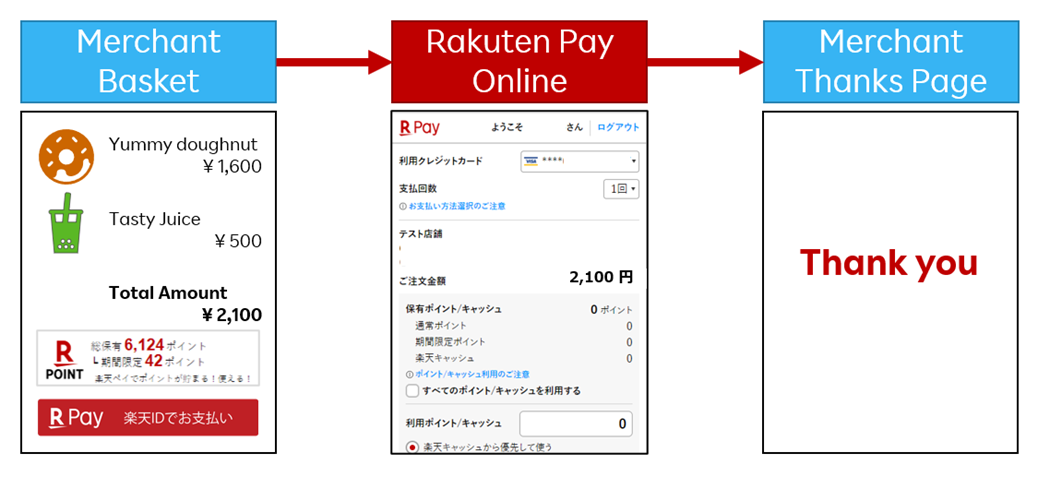
The number of people who shop at e-commerce sites increased from the effect of the COVID-19 pandemic. Thanks in part to those who continue to shop at e-commerce sites post-pandemic, the number of customers who choose to use Rakuten Pay (online payment) continues to increase. If you would like to know at which sites you can use Rakuten Pay (online payment), please check here (in Japanese only).
Why is improving HA/DR important to us?
Here comes the main part. As I mentioned above, we also offer Rakuten Pay (online payment) to e-commerce sites other than Rakuten Ichiba. If our service were to be suspended, the e-commerce sites would not be able to accept payments, which would not only cause inconvenience to shoppers but also lead to a loss of sales for the e-commerce sites.
For this reason, we focus on enhancing the HA/DR of the underlying Rakuten Pay (online payment) in our daily development and operation.
Five steps to improve HA/DR
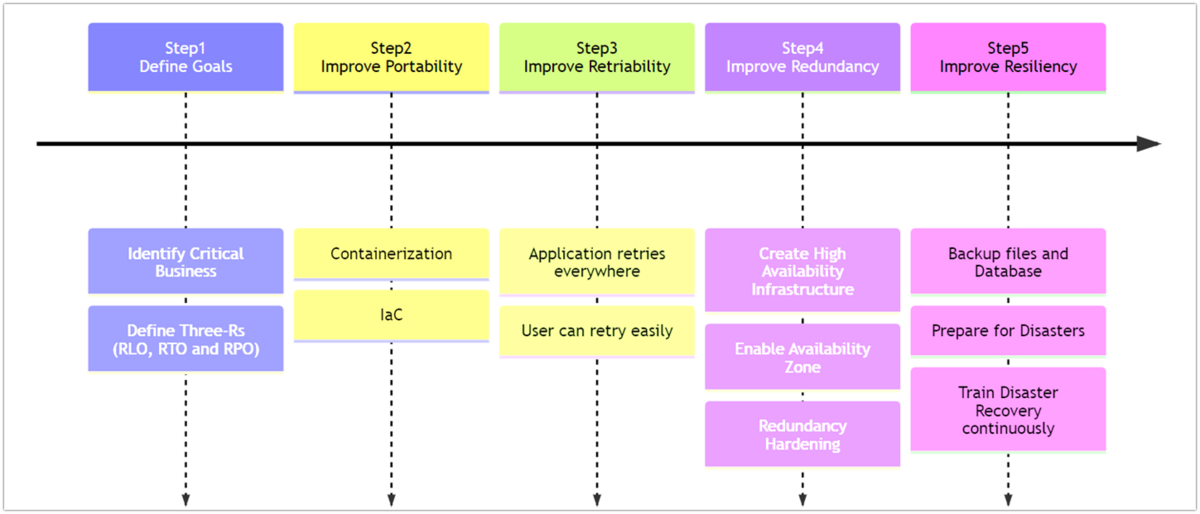
There are five major steps in achieving HA/DR as shown above. The actions to be taken at each step will vary depending on the size of the service, cost spendable on operation, and the team structure, so let’s check each step one by one.
Step1: Set the goal for HA/DR
First, since operational costs and team structure are closely related to the Business Continuity Plan (BCP), be sure to discuss the following three aspects defined in the BCP and costs with relevant parties.
Goal setting will change depending on the current business situation of the service. Review them periodically and set goals that take into account the service’s current state.
| Goal | Description | Factors to consider |
|---|---|---|
| RLO (Recovery Level Objective) |
What are the minimum functions to run? What is the minimum availability rate to aim for? |
What are the key functions used by users? Are there any functions that can be temporarily operated manually or operations that can wait for recovery? |
| RTO (Recovery Time Objective) | Aim for recovery in how much time? |
How long would an optimistic recovery scenario take? How long would a pessimistic recovery scenario take? What is the opportunity loss/social impact that will occur during shutdown? Financially, how much operational cost can be applied? (Non-refundable insurance) |
| RPO (Recovery Point Objective) | Until which point is data loss acceptable? |
How often is the data updated? Can the lost data be recovered by other means? Are there any laws, regulations, etc. relevant to the retention of data? |
These above three Rs, RLO/RTO/RPO, have a significant impact on system complexity and operating cost. In the event of a failure, you may have to decide to give up some functions or data. Try to set goals while making such contingency assumptions.
Since goal setting has a significant impact on the architecture design in “Step 5: Improve resiliency” described later, it is desirable to complete it in advance rather than putting it off.
Step2: Improve Portability
In Step2, you will improve portability. Portability refers to the degree to which assets such as developed applications can be easily operated in any environment and whether the operating environment can be easily reproduced. The main objective of improving portability is to speed up delivery. Specifically, this refers to containerization and Infrastructure as Code (IaC) initiatives.
As you proceed with HA/DR, portability is the first issue you need to address as a team, and it is also the first hurdle you will encounter in terms of development style and cost-effectiveness.
Containerization is relatively easy to tackle, but the difficulty increases when dealing with IaC, especially in terms of management and training costs. Here are some of the reasons why it is recommended to work on portability first.
1. Subsequent Steps 3 to 5 are to be done on the assumption that portability is implemented.
2. Even if subsequent Steps 3 to 5 are not sufficiently addressed, it is possible to aim for recovery from a contingency if the cost and time are sufficient.
Step3: Improve Retry-Ability
In Step3, you will improve Retry-Ability. This term was coined by us. The following are its two key perspectives.
1. Always implement retry processing in the system to ensure that requests are processed correctly.
No matter how much you improve the availability rate, it will never be 100%. This is because it is difficult to completely prevent instantaneous network outages, communication delays, and instantaneous failures associated with failover from occurring. Therefore, it is recommended to implement retry processing at every I/O point (communication, file writing, etc.).
However, retry processing may seem simple, but it can cause data inconsistencies. For example, unlike connection timeout, in the case of query (or read) timeout, the request may have been sent, and processing may have been completed.
In some cases, implementing a simple retry process that considers the subsequent process as positive may be enough to ensure consistency. However, when more strict data consistency is required, it is necessary to perform transaction management for monolithic services, or to create compensating transactions or TCC (Try-Confirm/Cancel) patterns for microservices. For reference, below is a sequence diagram of retry processing using compensating transaction.
[Example of compensating transaction implementation]
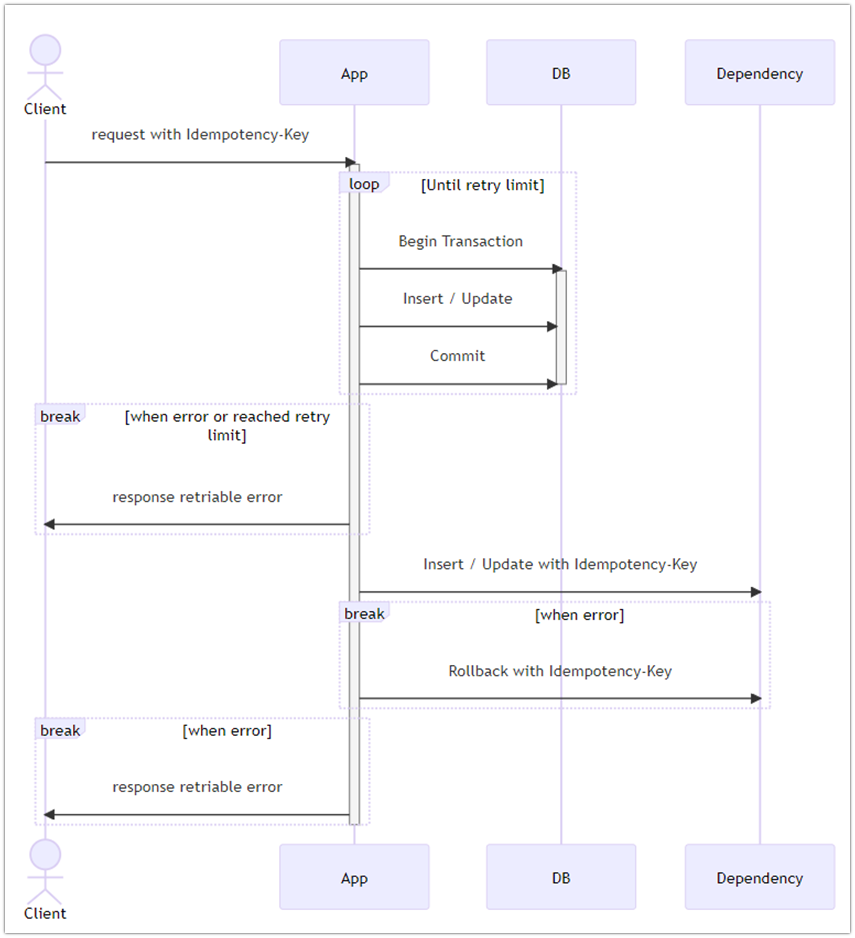
2. Design the system so that users can easily perform retry processing.
Even if retry processing is implemented on the system side, there will be cases where retries cannot be completed. Even in such cases, it is important to take fail-safe measures to ensure that subsequent processing is not affected by data inconsistencies as much as possible.
One example of a countermeasure is to design the system so that users themselves can easily rerun the retry process so that subsequent processes are quickly re-executed. To this end, it is recommended to mind the processing flow and on-screen behavior when errors occur when designing the system.
Step4: Increase Redundancy
In Step4, you will increase redundancy. Increasing redundancy means multiplexing the system to achieve a state in which the system operates normally throughout the entire system, even if some systems fail to operate properly due to malfunctions or other reasons.
However, it should also be noted that measures to improve redundancy will add switching and disconnecting processes, which may become a new cause for instantaneous failures.
1. Build infrastructure configurations with high availability
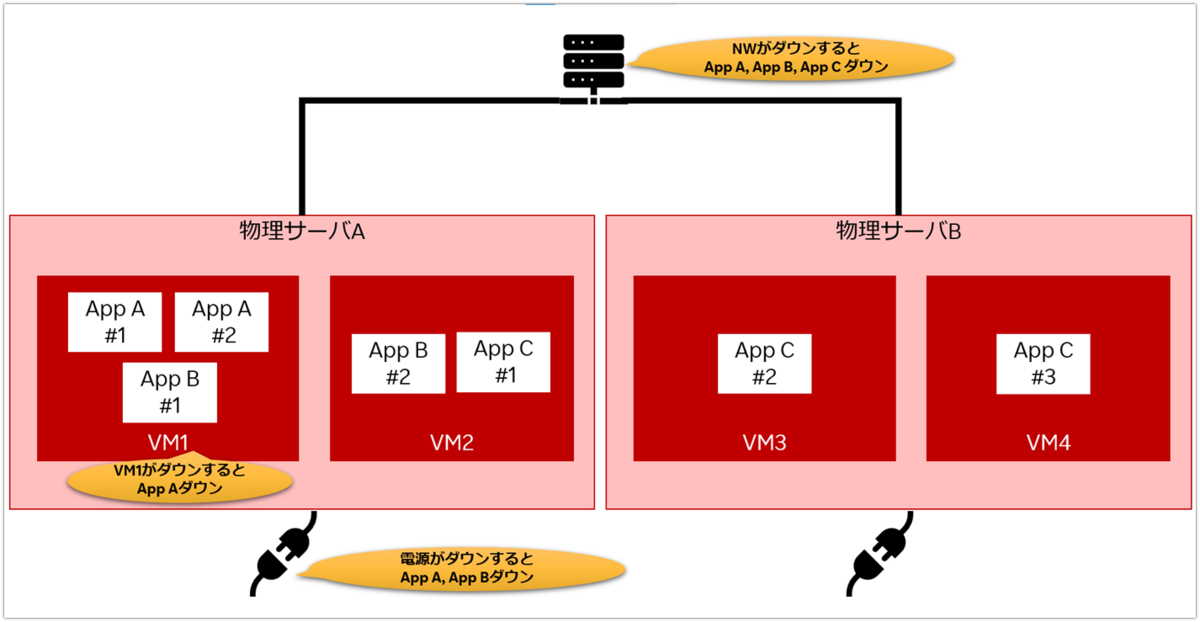
First, identify single points of failure one by one and multiplex/cluster them.
A single point of failure is a component of a system that, if it stops, will cause the entire system to stop.
The important point for multiplexing is that network, power supply system, virtualization server, etc. are physically separated. Isolating these elements will ensure the availability of the system. Also, when clustering, instances of the application must be able to run on physically different servers.
Some services may not be on-premise, but may use public clouds, for example. In such cases, a highly available infrastructure configuration can be achieved by setting the Availability Zone appropriately.
Below, I have picked out a few places that could be single points of failure. Readers are encouraged to firstly check from the same perspective.
2. Establish operational procedures that maintain redundancy.
Even if a highly redundant configuration is set up, if requests are sent to a server or application that has gone down for an extended period, the success rate of the request will decrease. Therefore, it is also important to establish operational procedures for quick disconnection and failover.
Manual operation is fine at the start of service, but it is ideal to establish efficient procedures for disconnection and failover while performing operations, and eventually automate the operational procedures.
Step5: Improve Resiliency
In Step5, you will improve resiliency. In this step, you will aim to be able to recover from a complete system downtime.Although the previous steps have introduced several points for ensuring continuous normal operation of the system, there will always be cases, such as large-scale disasters or power outages, in which an entire system shutdown is inevitable. You should be prepared to restore service quickly in such cases.
Specific measures to improve resiliency include securing backups and running systems at remote locations. When selecting measures to implement, it will be necessary to examine the appropriateness of each measure by estimating the operational cost of implementing the measure, the service recovery time, and the amount of loss from the service interruption. As an example, the following graph shows the relationship between operational cost and service recovery time when each measure is implemented.

*Data and figures are for reference only.
The above graph also shows that the measures and KPIs to be set for each service differ depending on the scale of the system and the amount of loss in the event of service interruption. Measures with higher intensity and shorter recovery time will have higher operational cost. Therefore, it would be realistic to gradually aim for an Active-Active state along with the growth and expansion of the service.
It is also important to prepare for emergencies on a regular basis by regularly updating procedure manuals and conducting disaster drills for IT systems so that members can quickly take system recovery procedures (failover procedures, etc.) in an emergency.
Summary
Thank you for reading! I hope that through this article, you have gained a deeper understanding of HA/DR and BCP and can now take practical action.
In the next article, I will introduce specific examples of how the approach I have introduced so far is actually utilized in the development of Rakuten Pay (online payment)!
Hiring Information
We are looking for developers who can work with us! Please see the link below for details.
Hiring information: Rakuten Pay (online payment)