

Hi, I’m Nana, the Tech Lead for Rakuten Pay (online payment). In this article, I will introduce the specific initiatives we take to improve High Availability/Disaster Recovery (HA/DR) in the operation of Rakuten Pay (online payment).
The previous Part 1 article covered a more general description of the approach we have developed in operating and managing our large -scaled service, Rakuten Pay. If you are interested, please also check it out!
Five steps to improve HA/DR
Here is a recap of the five steps to improve HA/DR described in the previous article. Our team, which operates Rakuten Pay (online payment), also follows these five steps to improve HA/DR.
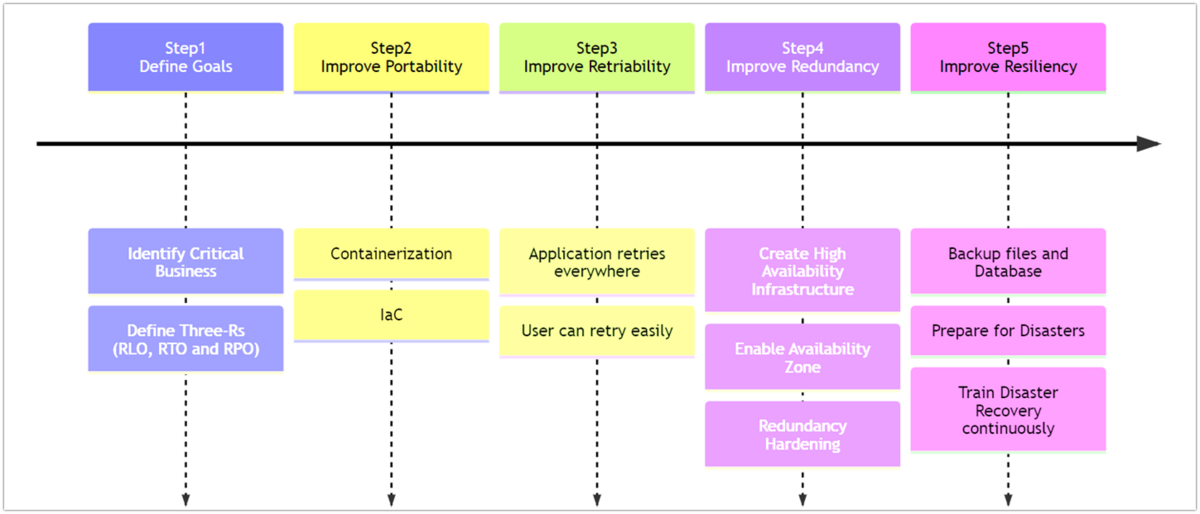
What are the five steps?
Step1. Set the goal for HA/DR: Set the three Rs (RLO/RTO/RPO) included in the Business Continuity Plan (BCP).
Step 2. Portability: Aim for a state in which assets such as developed applications can be easily operated in any environment and the operating environment can be easily reproduced.
Step 3. Retry-Ability: Aim for a system design that facilitates retry processing by including retry processing in the processing flow or by enabling user-operated retry processing.
Step 4. Redundancy: By multiplexing the system, aim for a state where the entire system operates properly, even if parts of the system do not work properly due to malfunctions or other reasons.
Step 5. Resiliency: Aim to be able to recover from a complete system downtime
Please see the previous article for details.
Step1: Set the goal for HA/DR
* I will omit details as it would include company strategies and specific figures.
Step2: Improve Portability
In our case, we sort out the parts that can be containerized at the application level and the parts that can be coded at the infrastructure level for each function or service to ensure portability.
1. Containerization at application level
Primarily, modularization at the application level means containerization. As for container builders, the latest trend would be to use Buildpacks, but we currently use Dockerfile to create images.
Using Dockerfile gives greater flexibility but makes it more prone to accidents in terms of security and reproducibility. As a preventive measure, we prepare a base image which can be commonly used by all applications, and each application uses this image to prevent accidents.
2. Coding at infrastructure level
Coding at infrastructure level is called Infrastructure as Code (IaC). While working on IaC, it would be a good idea to gradually make the infrastructure configurations available as modules as the service expands.
In our case, we use Terraform to manage the infrastructure configuration of multiple Active/Standby environments in one place. Unified modules allow you to efficiently build and manage multiple environments with minimal configuration.
To proceed with IaC, it is important to eliminate manual operations and encourage all members to develop a deeper understanding of the infrastructure. Manual operation reduces reproducibility and can lead to bugs and unexpected errors. In order to eliminate manual operations, it is ideal to remove all engineers' sense of weakness in infrastructure (especially about NW and security), so that all members can have a better understanding of IaC.
It took about two years for our team to adopt the IaC-based development system. For example, we created a system in which infrastructure engineers work with application engineers as reviewers when changing the infrastructure configuration. Also, application and infrastructure engineers designed together before developing features. Even so, there is always room for improvement. The members are still considering ways to improve the infrastructure configuration.
Step3: Improve Retry-ability
In case of Rakuten Pay (online payment), the goal when an error occurs is not only to recover to the pre-processing state with no data inconsistencies, but also to move forward to a state where data processing is complete.
In general, there are several design patterns related to retries. For example, in compensating transactions, the process will be canceled when an error occurs. However, our service has a logic that checks the status of the dependent service first and decides whether to proceed with the transaction or not, so that payment process can be completed as much as possible. So, in some cases, the intended process can be completed without resending the request.
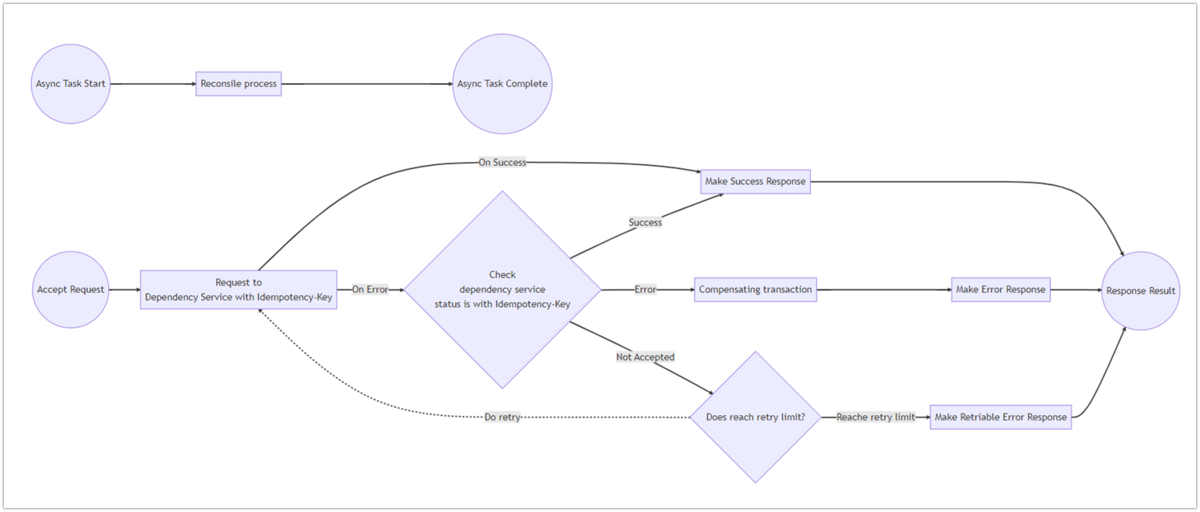
In cases where communication with the dependent service is intermittently failing, the communication of the cancellation process will also fail, so the integrity of the data cannot be fully guaranteed by the compensating transaction alone. Assuming such cases, we regularly run a reconcile process separately to resolve inconsistencies with dependent services as an asynchronous process to ensure data consistency in a complementary manner.
Step4: Ensure Redundancy
In our case, since we use a public cloud, redundancy is ensured at the infrastructure layer by enabling Availability Zones (AZ) and by increasing the number of instances to two or more. At the application layer, we ensure redundancy by running Kubernetes (k8s) across AZs while setting the number of instances to two or more. However, this alone is not enough to ensue complete availability at the application layer.
To further increase availability, we apply the following settings to k8s.
| Setting item | What we want to prevent/do with the setting |
|---|---|
| PodDisruptionBudget | When restarting due to node failure, prevent pods from going down at the same time |
| ResourceLimit | Limit the resources that can be occupied when the load of a particular application increases so as not to affect the performance of other applications |
| LivenessProbe | Prevent broken pods that are not running properly from remaining in a running state and hogging resources, and re-execute the process |
| ReadinessProbe | Safely disconnect pods where processing is likely to fail |
| NodeSelector & NodeAffinity | Physically separate specific high load batches and front applications that affect end-users so that end-user usage is not impacted |
| PodAntiAffinity | Allow pods that run an application to be deployed across multiple nodes to diversify risks so that if one node fails, the entire service does not stop |
The above settings can be configured in the Deployment Yaml file as shown below.
Deployment Yaml
apiVersion: policy/v1
kind: PodDisruptionBudget
...
spec:
minAvailable: 50%
selector:
matchLabels:
app: <app-name>
...
apiVersion: apps/v1
kind: Deployment
...
spec:
replicas: 2
template:
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- <app-name>
topologyKey: "kubernetes.io/hostname"
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: app-category
operator: In
values:
- web
containers:
- name: <app-name>
…
resources:
limits:
memory: 1024Mi
cpu: 1000m
readinessProbe:
...
livenessProbe:
...
Step5: Improve Resiliency
We currently use an Active-Standby configuration where multiple systems are prepared and are put on standby. In general, the environment is prepared with the following three categories. We calculate in advance the Recovery Point Objective (RPO) set in Step1 as well as the operating costs and Recovery Time Objective (RTO) and consider the optimal combination of measures before implementation.
In pursuing HA/DR, it is very important to consider how to combine the three categories to create an environment that is cost-effective between RTO/RPO and operational costs.
| Category | Definition | Operating cost | Time required for recovery | |||
|---|---|---|---|---|---|---|
| On-Demand (Cold Standby) |
A backup environment is coded in advance and provisioned in Terraform as needed. *In general, Cold Standby is defined, but we define as On-Demand as in the cloud, an environment may be deleted when it is in stopped state. |
None | Long | |||
| Warm Standby | A backup environment is built in advance and kept in stopped or fallback state. | Small | Medium | |||
| Hot Standby | A backup environment is built in advance and always kept in activated state. | Large | None to Short | |||
Also, it is easy to forget that when you code your On-Demand backup environment in advance, you should remove resources after undergoing a security audit and NW system design/connection to ensure that it is reproducible and safe to build from scratch.
Finally, below is a system configuration of the production and standby environments for your reference. It should be noted that requests from users are always accepted at GSLB, and that both production and standby environments are designed to include IP and domain information of the standby system in advance so that the environment can be switched promptly, and this is registered in GSLB.
It may be difficult to imagine about warm standby in k8s, but we maintain only the master node, do not deploy any applications on it, and keep it in fallback mode with zero worker nodes. If a problem occurs in the production environment, our engineers will create a group of resources in the standby environment, promote them to the production environment, and then change the route from GSLB in order to recover the system.
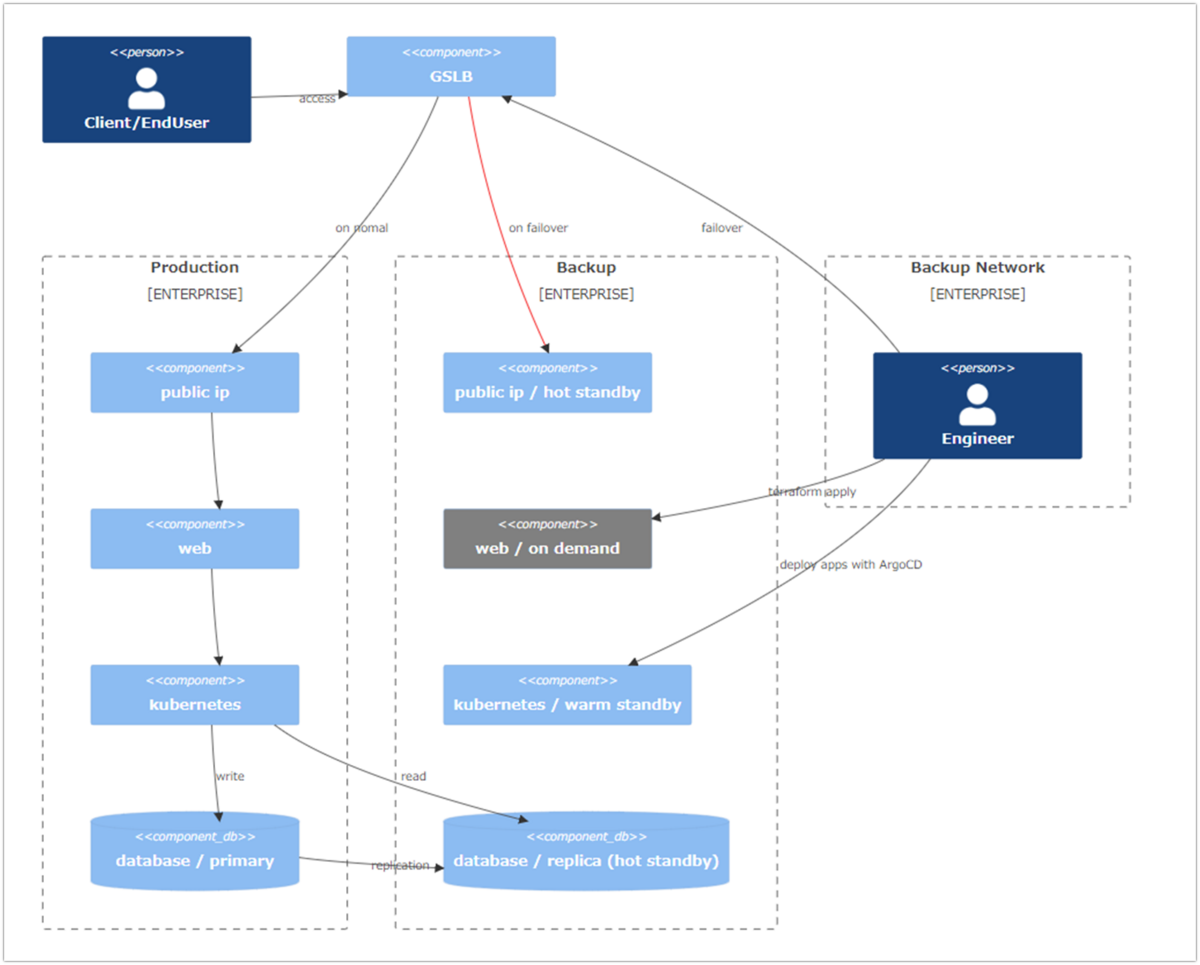
In addition, we regularly conduct emergency drills and verify procedures so that we can promptly switch from the backup environment to the production environment in the event of a problem.
Summary
How was the article? This article introduced an example of how Rakuten Pay (online payment) implements its actual infrastructure configuration.
I hope that this article, along with the previous one, will be of some help to you in actually taking action. Thank you for reading!
Hiring Information
We are looking for developers who can work with us! Please see the link below for details.